系統架構筆記 - 垂直擴展、水平擴展
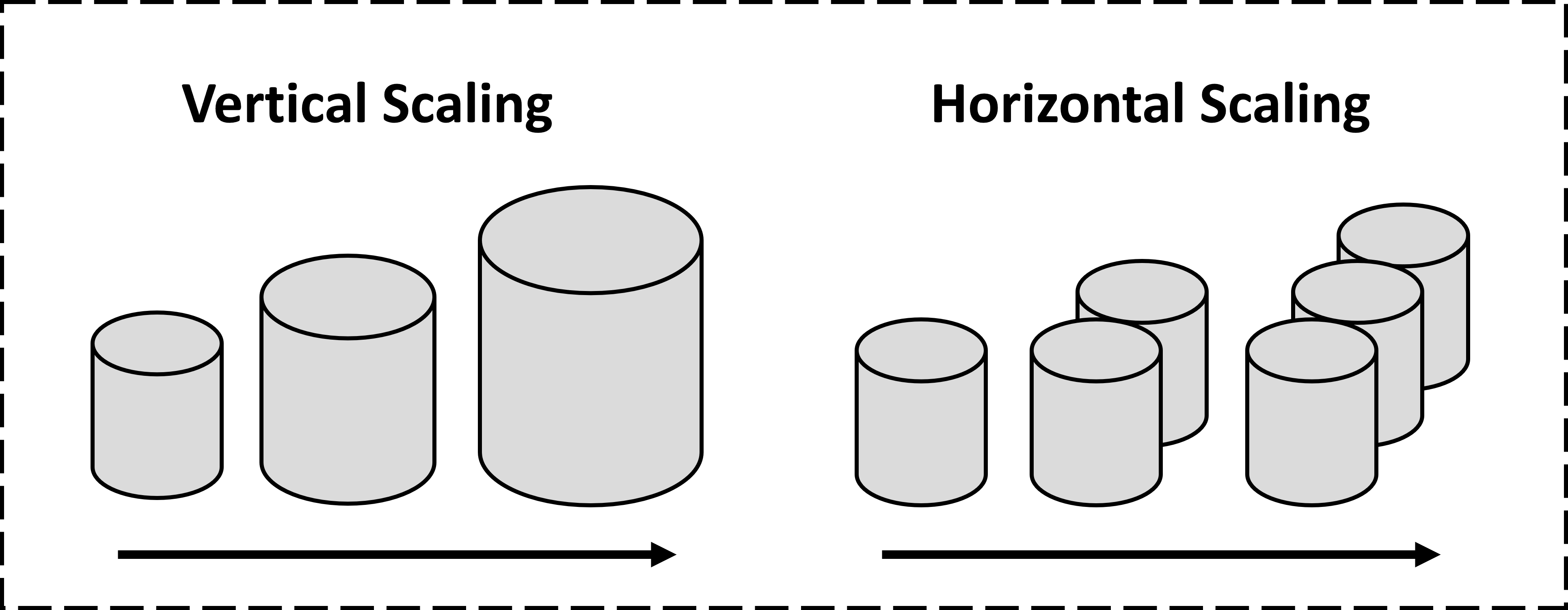
這篇文章會介紹垂直擴展以及水平擴展,並以資料庫的水平擴展為延伸,介紹讀寫分離與資料庫切分 (Sharding)。
垂直擴展
這台機器不行那我就換一台更好的。
其實就是升級硬體,好處就是簡單直接,能用垂擴展解決那就優先考慮垂直擴展吧。但垂直擴展是有極限的,而且越好的機器越貴,這時就可以考慮水平擴展。
水平擴展
一台機器不行那我就多用幾台。
要實現伺服器的水平擴展比較容易,不外乎就是多開幾台機器,然後做好 load balance,這裡重點介紹資料庫的水平擴展,大致上可以分為兩個策略:
讀寫分離
在原本的資料庫 (主節點) 外添加幾個從資料庫 (從節點) ,向主節點寫入資料,讀取時則優先自從節點讀取。讀寫分離會遇到幾個問題:
- 最終一致性問題
由於從節點的數據是自主節點同步過來,因此中間勢必存在一時間差,可能導致從節點的數據不是最即時的數據,因此從節點的數據僅滿足最終一致性。 - 單個主節點
由於主節點仍然只有一個,如果遇到需要大量寫入的作業仍然會出現堵塞,這時候可能要考慮多個主節點的架構,不過就跟前一點一樣會遇到資料同步的問題,還需要考慮同時有多個寫入情況下的 race condition。
資料庫切分 (Partitioning / Sharding)
將一個資料庫 (大資料表) 分割為多個小資料表,並將其儲存在不同節點上,又可以分為垂直切分與水平切分:
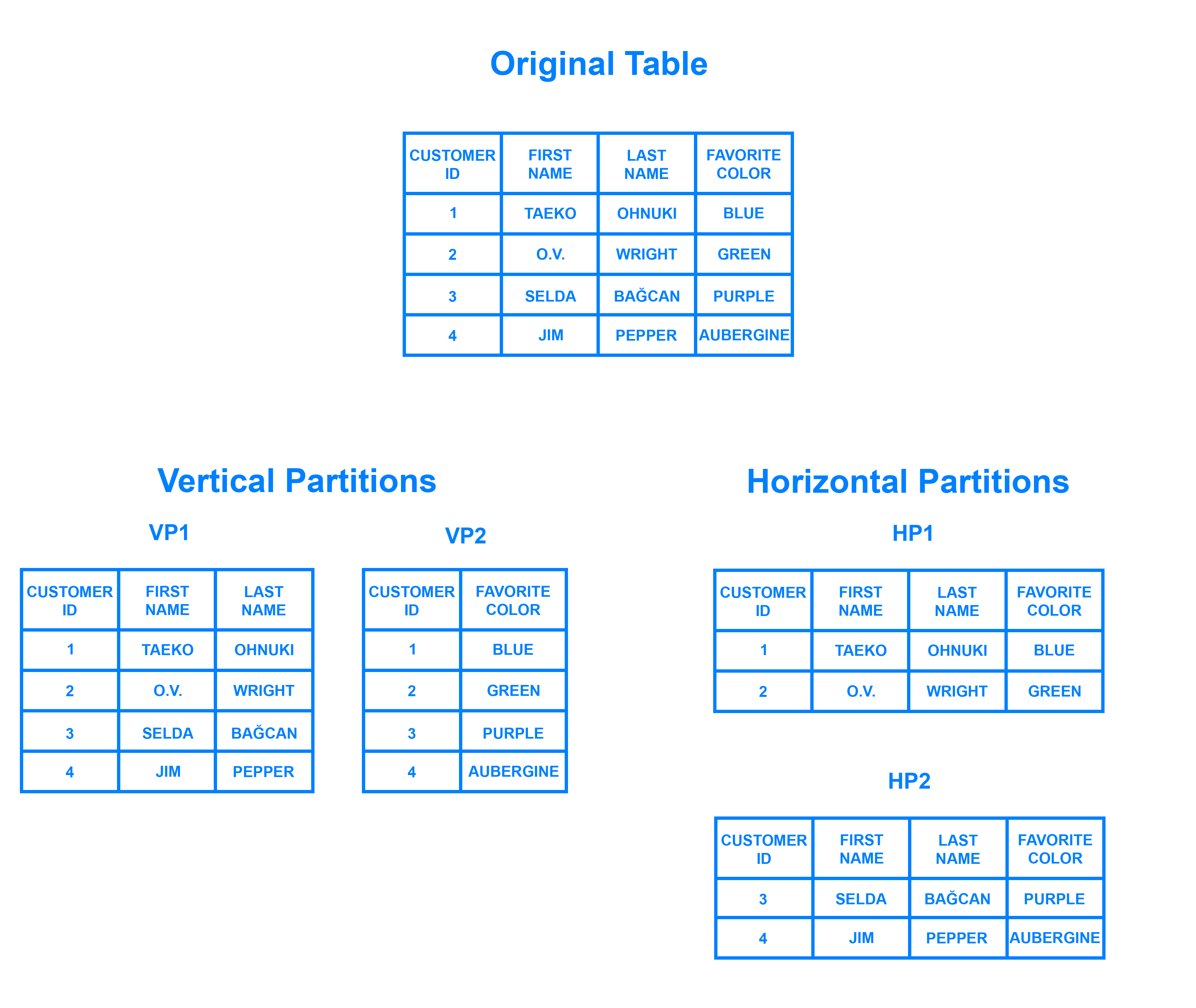
垂直切分
按照欄位來進行切分,通常可以按照業務功能來做切割,如電商平台中的買家資訊與賣家資訊就可以分開儲存。
水平切分
按照列來進行切分,主要有兩種切分方法:
- 按一定範圍切分
舉例來說 ID <= 10000 為第一個表,接著每 10000 筆資料為一個表,這個做法的好處是容易新增表,壞處是較差的附載平衡,因為新資料與舊資料的活躍度可能有很大的差異。 - 使用哈希表切分
將 ID 放入一個 Hash Function 中,如10 % 3 = 1,根據 Hash 結果找到對應的表,好處是有較佳的附載平衡,缺點是不容易新增表,新增一個表通常涉及到修改 Hash Function 以及原先表的數據遷移。
參考資料
Understanding Database Sharding
高并发(水平扩展,垂直扩展)
數據庫的向上擴展和橫向擴展(即水平擴展:讀寫分離、垂直切分、水平切分)