遍歷台北捷運109個車站要花多久時間? 基於 Held Karp 算法尋找最佳路線!
前言

台北捷運最近推出了一個很瘋狂的集章全制霸活動,集滿5條捷運路線(不含環狀線),總共109個車站,就可以抽大獎,到底有誰會閒閒沒事想參加這個活動? 啊,我女朋友剛剛問我要不要參加,沒事沒事,真是個好活動! 問題來了,該如何用最短的時間集齊所有車站並回到出發地呢?
本文將使用 Held Karp 算法來計算從台北車站出發,遍歷 109 個車站,並在最後回到台北車站所需花費的最短時間與路徑,不想看過程的人也可以直接到最後面看結果。XD
旅行推銷員問題
肯定有人發現了,這本質就是一個旅行推銷員問題,可以簡稱為TSP問題 (Travelling salesman problem)。借用維基百科的介紹,其問題內容為「給定一系列城市和每對城市之間的距離,求解訪問每座城市一次並回到起始城市的最短迴路。」
我們可以使用台北捷運開放資料 API 中的 捷運路線基本資料 來建立 Graph,再搭配 TSP 算法理論上就能算出最佳路徑與花費時間了,為了方便計算先不考慮班次跟轉乘時間了。另外,雖然環狀線不在集章活動的範圍內,但身為一條「捷徑」,肯定還是要考慮進去的。
- 資料格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25lines = [
{
"LineNo": "BL",
"LineID": "BL",
"RouteID": "BL-1",
"TrainType": 1,
"TravelTimes": [
{
"Sequence": 1,
"FromStationID": "BL23",
"FromStationName": {
"Zh_tw": "南港展覽館",
"En": "Taipei Nangang Exhibition Center"
},
"ToStationID": "BL22",
"ToStationName": {
"Zh_tw": "南港",
"En": "Nangang"
},
"RunTime": 112,
"StopTime": 0
},
... and more
] - 建 Graph
1
2
3
4
5
6
7
8original_graph = defaultdict(dict)
for line in lines:
for edge in line["TravelTimes"]:
start = edge['FromStationName']['Zh_tw']
end = edge['ToStationName']['Zh_tw']
time = edge["RunTime"]
original_graph[start][end] = time
original_graph[end][start] = time
Held Karp 算法
Held Karp 算法是基於動態規劃來求解TSP問題的一種算法,簡單來說,這個算法會遍歷所有可能的狀態,包括已訪問節點與所在節點,並根據當前狀態下去計算下一步該如何走。
為了記錄所有可能,我們可以用 binary 來表示已訪問節點,1表示已經過,0表示還沒經過,舉例來說
- 000: 表示尚未訪問任何節點
- 001: 表示已訪問第1個節點
- 101: 表示已訪問第1跟第3個節點
Held Karp 算法理論上能求出最佳解,可惜時間複雜度高,將已訪問節點 x 當前節點 x 下一節點 ,會得到時間複雜度是
Anyway,時間複雜度那麼高,最多也就容許圖中有20~25個節點,台北捷運109個站是要算到天荒地老? 所以我們的下個目標是要將 Graph 縮小!
BTW, 因為算法需要知道任意兩點之間的成本,所以下文中任意兩點間的距離使用 Dijkstra 來計算最短路徑。
Cut the tails and circle
仔細觀察捷運圖,會發現大部分捷運尾巴的部分是可以分開計算的,比如民權西路到淡水、大安到動物園等,直覺上來說這些路線肯定只能原路折返,更準確地講我們可以不斷地將 indegree 為 1 的節點移除掉,用剩餘的節點計算就好。
接著看到文湖線與板南線圍起的圓圈,如果你今天要用最快的時間遍歷圓圈內的所有車站,你會怎麼走這個圓圈? 要馬順時鐘繞完要馬逆時鐘繞完,絕對不會有繞一半往回走的情況,所以這一段我們也可以先移除。
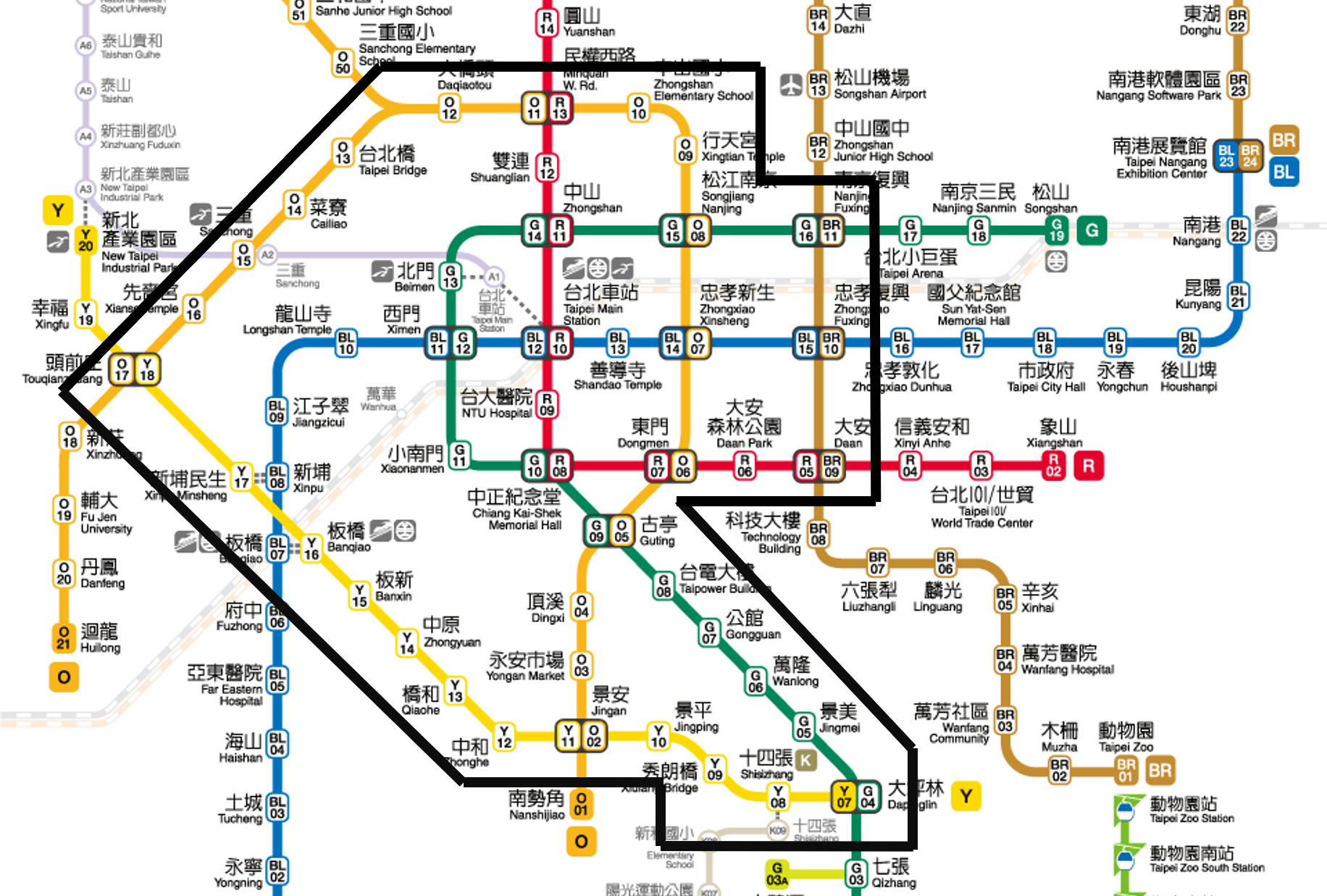
1
2
3
4
5
6
7
8
9
10
11tails = [
('淡水', '民權西路'), ('新北投', '北投'), ('蘆洲', '大橋頭'),
('迴龍', '頭前庄'), ('頂埔', '板橋'), ('南勢角', '景安'),
('新店', '大坪林'), ('小碧潭', '七張'), ('松山', '南京復興'),
('動物園', '大安'), ('象山', '大安')
]
# 拆成3段算,否則用最短路徑算會直接走下去
circles = [
("南京復興", "內湖"), ("內湖", "南港"), ("南港", "忠孝復興")
]
Compress path
算了一下,剩下的節點還是太多了啊,這時候就拿出第二招「路徑壓縮」,將不重要的節點從路徑中移除。舉例來說,從古亭到大坪林雖然要經過 4 站 (台電大樓、公館、萬隆、景美),但這 4 個站都在同一條線上且沒有分支,可以把它們當作是順便「路過」,將這些中間的節點移除,用頭尾的節點做計算就好。
前面提到的圓圈部分其實也能算是一種路線壓縮 (忠孝復興 <----> 南京復興),只留下頭跟尾,中間部分都省略。
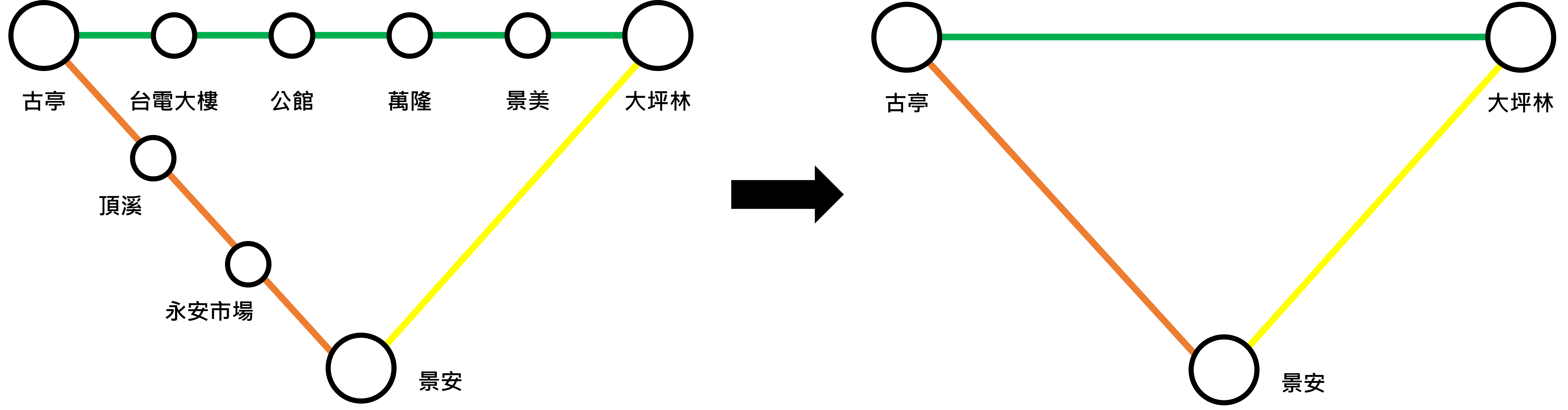
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# Key Stations
key_stations = [
'民權西路', '雙連', '中山', '台北車站', '台大醫院', '中正紀念堂',
'中山國小', '行天宮', '松江南京', '忠孝新生', '東門',
'古亭', '南京復興', '忠孝復興', '大安', '北門', '西門',
'小南門', '善導寺', '頭前庄', '板橋', '景安', '大坪林'
]
# compress path
n = len(key_stations)
graph = [[0]*n for _ in range(n)]
sub_paths = defaultdict(dict)
for start_idx in range(n-1):
for end_idx in range(start_idx+1, n):
cost, path = dijkstra(original_graph, key_stations[start_idx], key_stations[end_idx])
graph[start_idx][end_idx] = cost
graph[end_idx][start_idx] = cost
sub_paths[start_idx][end_idx] = path
sub_paths[end_idx][start_idx] = path[::-1]
如果我們只用頭跟尾去計算最佳路線,那我們要如何保證算法會經過那些被我們刪掉的節點呢? 同樣舉圓圈部分為例,要走入圓圈的前提是其中一段路的起點與終點分別是南京復興或忠孝復興,如果算出來根本不是這樣走呢?
其中一個解決方法是「提供誘因」,引誘算法選擇走這些路線,對於最短路徑算法來說,最大的誘因是什麼呢? 答案就是距離/時間,只要將兩點之間的距離/時間設為 0,那算法便會更偏好這條路徑。(當然,最後是會加回去的。)1
2
3
4
5
6
7
8
9
10
11
12# 引誘路線
key_paths = [
("忠孝復興", "南京復興"), ("民權西路", "頭前庄"), ("西門", "板橋"),
("古亭", "景安"), ("古亭", "大坪林"), ("大安", "東門")
]
adjusted_graph = [row[:] for row in graph]
for start, end in key_paths:
start_idx = key_stations.index(start)
end_idx = key_stations.index(end)
adjusted_graph[start_idx][end_idx] = 0
adjusted_graph[end_idx][start_idx] = 0
既然這個做法聽起來那麼讚,那就把看起來能壓縮的路線全部壓一遍吧? 很遺憾,也不是所有路線都管用,舉例,從民權西路經中山國中、行天宮到松江南京的路線,就算將距離設為0,在很多情況下算法還是不會經過,而是選擇走其他條路,具體來說究竟哪些可以壓縮哪些不行我也說不清楚,如果有想法的話歡迎提供建議! 整體來說,將路線密集區的節點保留起來,可以保留各種路線被算法嘗試的可能性。
算法實現
Held Karp
1 | from tqdm import tqdm |
Dijkstra
1 | import heapq |
完整程式碼
1 | from data import key_stations, key_paths, lines, tails, circles |
結果
終於來到本篇文章精華? 根據計算結果,從台北車站出發,遍歷 109 個車站,並在最後回到台北車站所需花費的時間是4小時52分鐘7秒,核心路線如下,記得遇到 tails 與 circle 時要繞過去就行了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
231. 台北車站-->善導寺
2. 善導寺-->忠孝新生
3. 忠孝新生-->東門
4. 東門-->大安森林公園-->大安
5. 大安-->忠孝復興
6. 忠孝復興-->南京復興
7. 南京復興-->松江南京
8. 松江南京-->行天宮
9. 行天宮-->中山國小
10. 中山國小-->民權西路-->雙連-->中山
11. 中山-->雙連
12. 雙連-->民權西路
13. 民權西路-->大橋頭-->台北橋-->菜寮-->三重-->先嗇宮-->頭前庄
14. 頭前庄-->新埔民生-->板橋
15. 板橋-->新埔-->江子翠-->龍山寺-->西門
16. 西門-->北門
17. 北門-->西門-->小南門
18. 小南門-->中正紀念堂-->古亭-->頂溪-->永安市場-->景安
19. 景安-->景平-->秀朗橋-->十四張-->大坪林
20. 大坪林-->景美-->萬隆-->公館-->台電大樓-->古亭
21. 古亭-->中正紀念堂
22. 中正紀念堂-->台大醫院
23. 台大醫院-->台北車站
不過說真的,雖然路線可能是最好沒錯,但這個計算結果肯定是低估多了,原因如文章中所提,並沒有將班次與轉乘的因素考慮進去。
再者,這只是「遍歷」所花費的時間,大家還記得活動的目的是要集章嗎? 這些集章的機台大多都在站外,也就是你各位要出站啊 😂😂😂,保守一點算,假設每站要多停留5分鐘,換算下來差不多就要再多個 9 小時,這還只是保守,想買捷運一日票在一天內集齊所有章不是不可能,但這表示一大早就要開始集章,並且整天都要很認真地跑路線才能辦到,實在太累人了啊,這裡強烈建議:
“買月票或跟有月票的朋友借,分幾天慢慢跑完,比較輕鬆還不用多花半毛錢喔” 😉